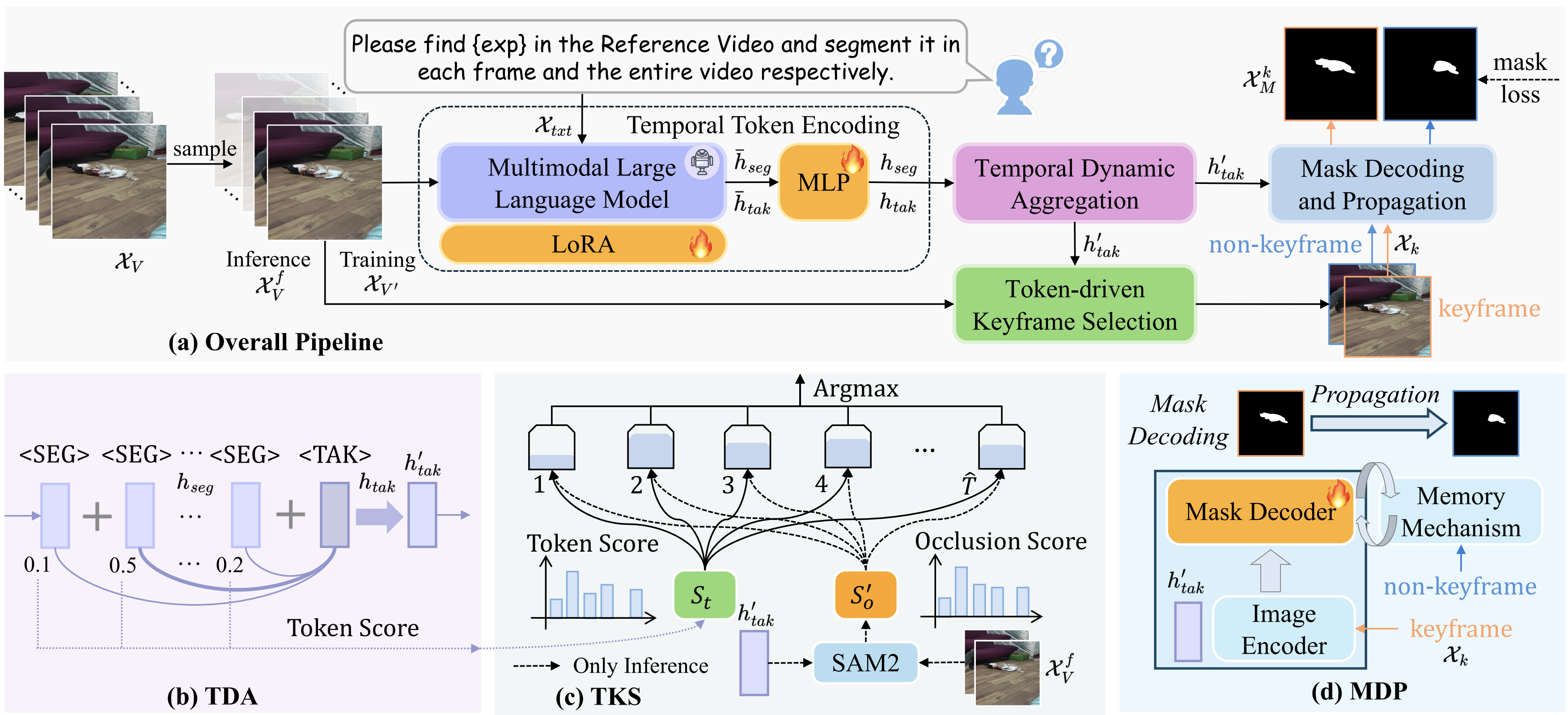
Comparison with Previous Methods
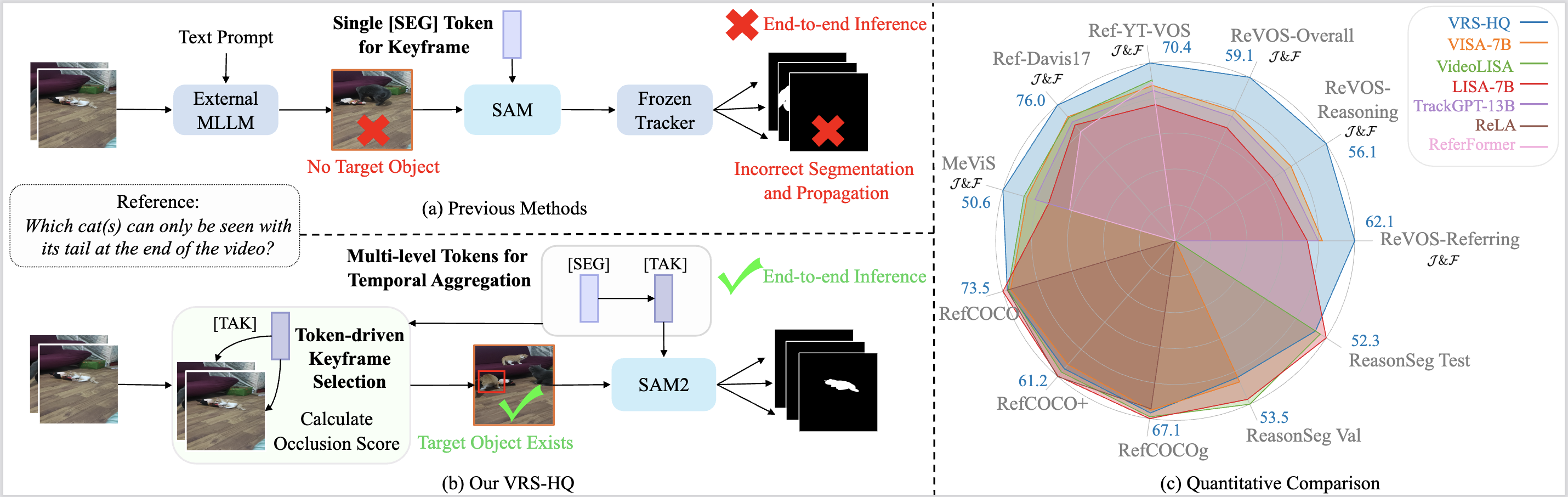
Comparison with previous VRS approaches.
(a) Previous methods utilize a single <SEG> token for keyframe-based segmentation, depending heavily on external models for keyframe detection and mask propagation. This reliance can hinder accurate keyframe localization and prevent end-to-end inference.
(b) In contrast, VRS-HQ introduces frame-level <SEG> and a temporal <TAK> token for dynamic aggregation. The aggregated <TAK> token is then used for both keyframe selection and mask generation within SAM2. This enables single-stage inference with precise keyframe selection and high-quality segmentation.
(c) VRS-HQ achieves state-of-the-art per- formance on various image and video datasets across reasoning and referring segmentation.
Comparison with previous VRS approaches. (a) Previous methods utilize a single <SEG> token for keyframe-based segmentation, depending heavily on external models for keyframe detection and mask propagation. This reliance can hinder accurate keyframe localization and prevent end-to-end inference. (b) In contrast, VRS-HQ introduces frame-level <SEG> and a temporal <TAK> token for dynamic aggregation. The aggregated <TAK> token is then used for both keyframe selection and mask generation within SAM2. This enables single-stage inference with precise keyframe selection and high-quality segmentation. (c) VRS-HQ achieves state-of-the-art per- formance on various image and video datasets across reasoning and referring segmentation.